LLMs在软件安全中的应用:漏洞检测技术综述与洞察
本文翻译自:LLMs in Software Security: A Survey of Vulnerability Detection Techniques and Insights,原文地址为https://arxiv.org/abs/2502.07049
作者:
- ZE SHENG,德克萨斯A&M大学,美国
- ZHICHENG CHEN,德克萨斯A&M大学,美国
- SHUNING GU,德克萨斯A&M大学,美国
- HEQING HUANG,香港城市大学,中国
- GUOFEI GU,德克萨斯A&M大学,美国
- JEFF HUANG,德克萨斯A&M大学,美国
摘要:
大语言模型(LLMs)正在成为软件漏洞检测的变革性工具。传统方法(包括静态和动态分析)在现代软件复杂性面前面临效率、误报率和可扩展性的限制。通过代码结构分析、模式识别和修复建议生成,LLMs展示了一种新的漏洞缓解方法。
本综述探讨了LLMs在漏洞检测中的应用,分析了问题表述、模型选择、应用方法、数据集和评估指标。我们调查了当前的研究挑战,强调跨语言检测、多模态集成和仓库级分析。基于我们的发现,我们提出了解决数据集可扩展性、模型可解释性和低资源场景的解决方案。
我们的贡献包括:(1)对LLMs在漏洞检测中应用的系统分析;(2)检查研究间模式和变化的统一框架;(3)关键挑战和研究方向的识别。这项工作推进了对基于LLM的漏洞检测的理解。最新发现维护于https://github.com/OwenSanzas/LLM-For-Vulnerability-Detection
附加关键词和短语: 大语言模型、漏洞检测、网络安全
1 引言
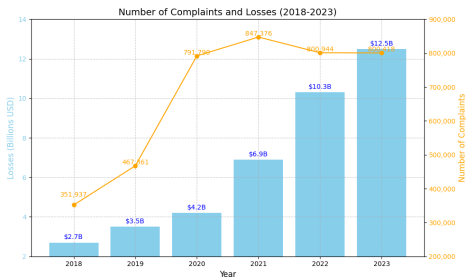
漏洞检测在现代软件的设计和维护中扮演着重要角色。统计数据显示,约70%的安全漏洞源于软件开发过程中的缺陷[4]。根据CVE编号机构(CNAs)提供的指标,过去5年中约有120,000个CVE被发现和报告[20]。根据图1中FBI的网络犯罪报告,2018年至2023年期间遭受了大量网络犯罪和投诉。最近的一个例子是2024年7月的CrowdStrike事件[110],其中一个有缺陷的软件更新导致医疗、交通和金融等关键基础设施部门广泛系统崩溃。因此,需要加强对漏洞检测技术的关注和投资。
最先进的漏洞检测方法/工具大致可分为静态分析和动态分析[18, 76, 100, 133]。静态分析检查源代码或字节码以识别潜在安全漏洞,而动态分析在程序执行期间进行,包括模糊测试[102]等技术。模糊测试通过向应用程序输入随机或特定无效数据并观察系统响应来识别潜在漏洞。然而,随着软件系统规模的增加,传统静态和动态分析方法都有明显的局限性。例如,静态和动态分析工具存在高误报率、低效率以及面对大量漏洞类型时需要大量投入的问题[54, 112]。
大语言模型(LLMs)作为自然语言处理(NLP)的进步,通过深度学习技术(特别是Transformer架构)训练,专注于各种NLP任务[111]。最近,LLMs在软件开发领域显示出卓越能力[51]。基于这些能力,研究人员提出了几种LLM驱动的漏洞检测方法和工具。这一新趋势吸引了网络安全专家和机器学习研究人员的关注,可能彻底改变这一领域。例如,2024年DARPA举办了人工智能网络挑战赛(AIxCC),参赛者仅利用通用LLMs(GPT系列、Claude系列和Gemini系列)进行漏洞检测、复现和修补[22]。该比赛汇集了全球网络安全和机器学习领域的领先专家,表明将LLMs应用于漏洞检测的巨大潜力。
LLMs在漏洞检测中的应用日益增多,从AIxCC等倡议中可见一斑,展示了其能力的快速演进和该领域方法的多样性。尽管兴趣日益增长且研究投入显著,但仍缺乏系统性的综述来彻底检查基于LLM的检测方法。
本文通过提出首个专注于理解LLMs在漏洞检测中优势和劣势的全面综述来填补这一空白。为提供结构化和整体分析,我们围绕四个关键方面构建综述:(1)识别适用于安全任务的有效LLM架构;(2)评估可靠评估的基准、数据集和指标;(3)分析技术以揭示最佳实践;(4)识别挑战以指导未来研究方向。这些方面共同突出了该领域的现状及其进步潜力。
基于这些方面,我们关注以下研究问题(RQs):
- RQ1. 哪些LLMs已被应用于漏洞检测?
- RQ2. 设计了哪些基准、数据集和指标来评估漏洞检测?
- RQ3. LLM用于漏洞检测使用了哪些技术?
- RQ4. LLMs在检测漏洞时面临哪些挑战及解决它们的潜在方向?
为分析和总结RQs,我们从500多篇论文中筛选了80多篇(其中58篇高度相关),以确保时效性(2019-2024年)和相关性(专注于LLMs在漏洞检测中的应用)。因此,本综述将不讨论2014年至2020年间主要使用的传统机器学习方法(传统CNN、RNN和LSTM)在漏洞检测中的应用。
总的来说,我们的关键发现可以总结为积极方面和关键差距:
积极方面:网络安全社区经历了LLM带来的积极影响,近年来发表文章大幅增加便是明证。贡献涵盖多个领域,包括漏洞定位、检测和分析。C、Java和Solidity已成为该领域的主要焦点。研究方法始终强调三个关键组成部分:LLM实现、提示工程和语义处理方法。此外,多智能体方法因将复杂漏洞检测挑战分解为可管理的子问题而被广泛使用。
关键差距:
- 范围狭窄和仓库级覆盖有限:当前工作通常局限于小型专业数据集中函数级漏洞的二元分类。此外,很少有研究解决仓库级的漏洞检测和复现,其中跨文件依赖和长调用栈带来了重大挑战。
- 前沿LLMs的快速进展:2023-2024年的突破表明,微调和利用前沿LLMs对未来进展至关重要,但迄今为止大多数研究仍依赖能力较弱的传统模型。
- 上下文意识不足:对复杂、多文件依赖和长调用栈的关注不足。尽管神经符号方法(如CodeQL、Bear与LLMs结合)在大规模项目上显示出潜力,但仍需要改进污点传播建模、更高效的LLM推理和跨语言适应。
- 漏洞类型不平衡:内存相关漏洞(如缓冲区溢出问题)的检测准确率不成比例地高,而逻辑漏洞仍然相对未被充分探索。
- 数据集限制:现有数据集范围狭窄且存在数据泄露问题。迫切需要专门为基于LLM的漏洞检测量身定制的专用综合数据集,以推动基础和应用研究。
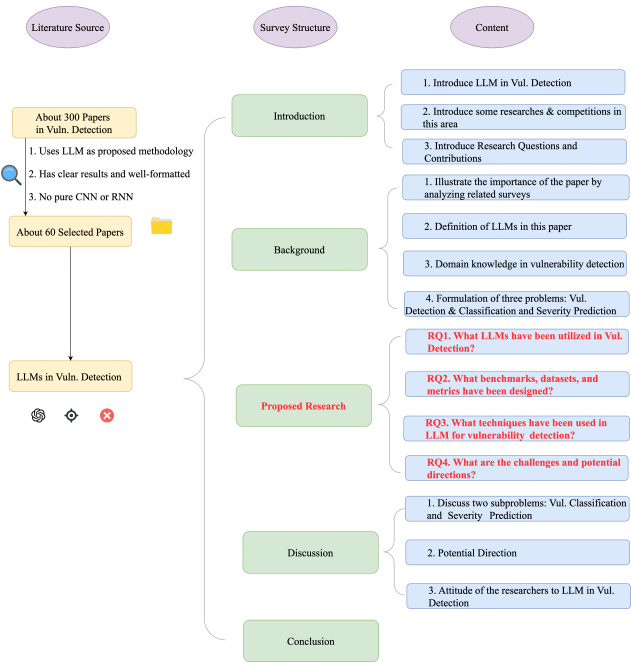
以下各节对LLMs在漏洞检测中的应用进行了全面分析。鉴于本综述的广泛范围,本节概述了我们分析的结构、主题和叙述流程。本文结构的可视化如图2所示
2 背景
2.1 论文选择与范围
为确保全面系统回顾,我们首先检索了顶级安全会议,如IEEE安全与隐私研讨会(S&P)、USENIX Security和ACM计算机与通信安全会议(CCS),以及期刊如IEEE软件工程汇刊。然后,我们通过提取会议和期刊论文中的关键词(如”漏洞检测”、”LLM”、”大语言模型”和”AI”)进行搜索。使用这些关键词,我们每三周进行一次迭代搜索,随时间推移优化选择。在两个月内,我们筛选了约500-600篇论文,并选择了58篇高度相关的研究。
本综述仅关注LLMs在漏洞检测中的应用,分析技术、数据集、基准和挑战。我们回顾了针对C/C++、Java和Solidity等编程语言的工作,这些是基于LLM的漏洞检测的主要焦点领域。专注于传统机器学习方法(如CNN和RNN)的研究,以及与漏洞检测无关的研究(如恶意软件分析或网络入侵检测)被排除在外。
在数据集方面,我们主要评估函数级和文件级粒度,注意到C/C++数据集在该领域占主导地位。然而,更好地反映现实开发场景的仓库级数据集显著缺乏。这一限制对LLMs泛化到复杂、多文件漏洞提出了挑战。
通过明确定义范围并采用严格的关键词驱动选择过程,我们旨在确保本综述的稳健性和相关性,同时为未来研究奠定坚实基础。
2.2 相关综述
过去五年中,许多研究提出了利用LLMs进行漏洞检测的方法。已有几篇关于漏洞检测技术的全面综述,涵盖了传统方法(静态/动态分析)和机器学习方法(CNN、RNN)[4, 15, 27, 134, 146]。但它们并未具体涉及LLMs在漏洞检测中的集成。Yao等人[129]回顾了LLMs在安全和隐私领域的应用,提出了其积极影响、潜在威胁和固有威胁。然而,他们的分析侧重于对这些问题的广泛概述,而非提供基于LLM的检测方法的方法论总结。Xu等人[124]概述了LLMs在整个网络安全领域的应用,包括恶意软件分析、网络入侵检测等。我们的综述特别关注基于LLM的漏洞检测,并对技术和方法进行了更详细的总结。同时,Zhou等人[140]调查了LLMs如何适应漏洞检测和修复。虽然他们的工作提供了宝贵见解,但我们的综述在几个方面有所不同:(1)截至撰写时,OpenAI和Anthropic都发布了更强大的LLMs(GPT-4o、o1和Claude 3.5 Sonnet),具有更强的推理能力和更大的上下文窗口;(2)我们对基于LLM的漏洞检测系统的基准和评估指标进行了全面分析;(3)我们更关注漏洞检测和理解的细节。
2.3 大语言模型(LLMs)
大语言模型(LLMs)已成为语言模型进化中的重要进展[138]。Transformer架构实现了前所未有的扩展能力。LLMs以其大规模为特征,通常包含在庞大语料库上训练的数千亿参数。因此,它在通用人类任务中带来了卓越能力[21]。
2.4 漏洞检测问题
2.4.1 领域知识
一些流行的漏洞数据库,如通用缺陷枚举(CWE)¹、通用漏洞披露(CVE)²、通用漏洞评分系统(CVSS)³和国家漏洞数据库(NVD)⁴,已被建立以记录常见漏洞的定义和评估。CWE关注软件开发生命周期(从开发到维护)中的所有漏洞。CWE不关注特定的现实世界安全漏洞(如Heartbleed和Log4Shell),而是关注这些现实世界漏洞的根本原因,如释放后使用(CWE-416)和越界写入(CWE-787)。CVE是一个识别和分类软件和硬件中安全漏洞的公共社区。该社区为每个现实世界漏洞分配唯一标识符。例如,Log4Shell的标识符是CVE-2021-44228。CVSS是一个通过多项指标(可利用性、影响、利用代码成熟度和修复级别等)评估漏洞风险级别的标准化框架。这些指标产生一个0到10的整体分数,严重性从低到严重。Log4Shell的CVSS分数为10(严重性:严重)。NVD是一个包含现实世界漏洞基本信息的数据库,如CVE标识符、漏洞技术细节、CVSS分数和缓解建议。例如,NVD记录Log4Shell可通过构造恶意JNDI语句远程在受害服务器上执行代码,这是由不当输入验证(CWE-20)和不受控制的资源消耗(CWE-400)引起的。
2.4.2 漏洞检测
漏洞检测是本综述中所有选定论文的核心焦点,代表了LLMs在软件安全中的主要应用。基本任务可以形式化定义为二元分类问题:
令 C
i
表示输入源代码,VD
i
代表LLM驱动的漏洞检测器。输出 Y
i
∈{0,1}表示漏洞状态,其中 Y
i
=1表示代码存在漏洞,Y
i
=0表示代码无漏洞。
图3显示了大多数选定研究中漏洞检测的示例工作流程,以及两个子问题:漏洞分类和严重性预测。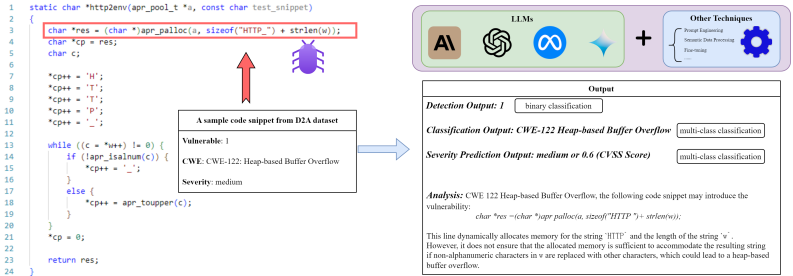
2.4.3 漏洞分类
除了二元检测,一些研究探索LLMs在多类漏洞分类中的能力,以增强模型可靠性。此任务要求LLMs不仅识别漏洞存在,还根据CWE等既定标准确定其具体类型。
形式化上,漏洞分类可定义为:令 C
i
表示输入源代码,VCi代表LLM驱动的漏洞分类器。输出Yi表示特定漏洞类型:Y
2
=VC
i
(C
i
)∈{type
1
,type
2
,…,type
n
},其中typei可以是漏洞名称(如缓冲区溢出、SQL注入)或标准化标识符(如CWE-119、CWE-89)。
例如,在检查代码片段时,LLM可能不仅检测到其存在漏洞,还将其分类为”CWE-79:跨站脚本(XSS)”,为安全缓解提供更详细指导。
2.4.4 漏洞严重性预测
一些研究将漏洞分析扩展到包括严重性预测以及检测。这可以表述为多类分类问题或回归任务,取决于严重性测量的粒度。形式化上,令Ci表示输入源代码,VSi代表LLM驱动的严重性预测器。输出Y可以定义为两种形式:它可能表示基于输入源代码C的漏洞严重性级别的严重性分数,如”低”、”中”或”高”。不同研究采用了不同的严重性预测方法:
- 分类分类: Alam等人[2]采用三级分类系统(高、中、低)进行直接严重性评估。
- 分数预测: Fu等人[35]要求LLMs预测0到10的数值CVSS分数,提供更精确的严重性测量。
这种额外的严重性信息有助于在实际应用中优先排序漏洞修复工作和更有效地分配安全资源。
3 研究结果
3.1 概述
我们的分析显示,基于LLM的漏洞检测研究主要集中在C/C++、Java和Solidity上。每种语言都有独特的挑战和研究重点。C/C++研究关注内存相关漏洞,这在该领域至关重要。Java研究解决框架特定漏洞和Web应用程序中跨组件的复杂交互。Solidity研究针对智能合约中的漏洞,这对区块链安全至关重要。
最近,大型仅解码器模型(如GPT和CodeLlama)因其规模化和强泛化能力成为主要选择。这些模型用于65%的微调实验。例如,Alam等人[2]微调了GPT-4,在Solidity漏洞检测中达到99%准确率。在此之前,仅编码器模型(如CodeBERT和GraphCodeBERT)被广泛使用。提示工程的进展也提高了检测性能。思维链提示现在常用于大型模型,并增强了它们对复杂代码的推理能力[24]。
当前大多数数据集关注函数级和文件级漏洞,C/C++是主要目标语言。例子包括Devign[145]和CVEFixes[6]数据集。然而,缺乏更好反映现实场景的仓库级数据集。这一差距限制了LLMs在漏洞检测中的实际应用。
未来研究应解决跨文件和复杂上下文漏洞检测中的挑战。应开发更好的代码语义表示方法,并创建现实的仓库级数据集。这些步骤将提高LLMs在该领域的适用性和可靠性。
3.2 RQ1. 哪些LLMs已被应用于漏洞检测?
本文中,我们使用Pan等人[94]概述的LLM分类和分类法,将主要LLMs分为三组架构:1)仅编码器,2)编码器-解码器,和3)仅解码器模型。由于空间限制,我们将简要介绍每个类别中的一些代表性LLMs。表1基于其固有能力和局限性,清晰概述了每类方法的优缺点。
仅编码器LLMs。 仅编码器LLMs仅使用Transformer模型的编码器组件[94]。这些模型专门设计用于分析和表示代码或语言上下文,而不生成输出序列,使其非常适合需要详细理解语法和语义的任务。通过使用注意力机制,仅编码器模型将输入序列编码为捕获基本语法和语义信息的结构化表示[47]。在软件工程(SE)领域,仅编码器模型如CodeBERT[30]、GraphCodeBERT[43]、CuBERT[55]、VulBERTa[45]、CCBERT[142]、SOBERT[50]和BERTOverflow[107]已被广泛使用。
编码器-解码器LLMs。 编码器-解码器模型结合了Transformer模型的编码器和解码器组件,使其能够处理需要理解和生成序列的任务。编码器处理输入序列,将其转换为结构化表示,然后解码以产生输出序列。这种结构使编码器-解码器模型适用于涉及翻译、总结或转换文本或代码的任务。著名例子包括PLBART[1]、T5[98]、CodeT5[117]、UniXcoder[42]和NatGen[14]。
仅解码器LLMs。 仅解码器LLMs专注于Transformer架构的解码器组件,以基于输入提示生成文本或代码。这种方法利用模型解释和扩展上下文的能力,使其通过预测后续标记来产生复杂连贯的序列。广泛采用于强调生成的任务,如漏洞检测和代码建议,仅解码器模型在识别代码中的相关模式和潜在问题方面表现出色。此类别中的著名例子包括GPT系列(GPT-2[97]、GPT-3[9]、GPT-3.5[91]、GPT-4[92]),以及专门为软件工程中的代码定制的模型,如CodeGPT[78]、Codex[16]、Polycoder[123]、Incoder[34]、CodeGen系列[90]、Copilot[40]、Code Llama[99]和StarCoder[64]。[143]
在分析58项漏洞检测研究时,我们识别了33种不同的LLMs用于各种任务。GPT-4成为最常用的模型,出现29次,其次是GPT-3.5,被提及25次。在类别中,仅编码器模型占总使用量的24.2%,其中CodeBERT、GraphCodeBERT、UniXcoder和BERT是突出例子。编码器-解码器模型(包括CodeT5)占使用量的8.7%,在代码生成和理解中扮演双重角色。仅解码器模型(如GPT系列、CodeLlama、StarCoder和WizardCoder)占总使用量的67.1%,主要应用于代码生成任务。
此外,表2展示了漏洞检测研究中最常用的前10种LLMs的架构和出现次数。它显示此任务的模型大多是仅解码器架构,表明该结构在检测任务中的广泛使用。尽管该领域普遍趋势通常偏爱仅编码器架构进行理解任务,但此表表明仅解码器模型也被广泛采用进行检测,可能因为其在代码分析中处理和生成相关序列的效率。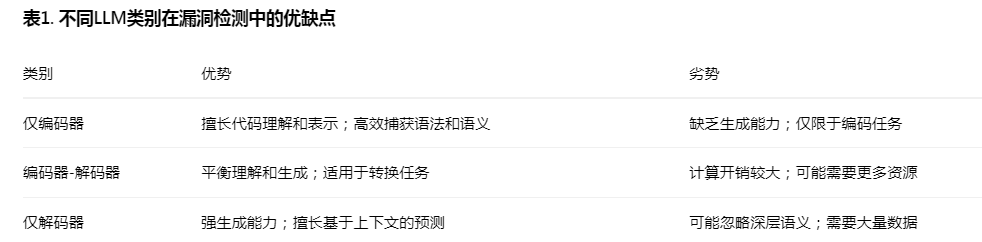
在所有LLMs中,GPT系列(尤其是GPT-4系列)因其在理解和生成代码方面的强大能力而表现一致良好。GPT-4被广泛认为适用于高级应用,如漏洞检测和代码分析,而GPT-3和GPT-3.5常在实证研究中作为基线或基准。专门模型(如CodeBERT和CodeT5)常用于涉及代码理解和处理的微调任务。一些研究结合多个模型,如将GPT-4与GPT-3.5配对,以评估比较性能或执行互补任务。这种集成方法结合通用LLMs和专门模型(如CodeBERT),利用了LLMs的泛化能力和专门模型的任务特定精度,从而提高了性能和多功能性。
RQ1答案
最近趋势显示研究从仅编码器模型转向大型仅解码器架构(如GPT和CodeLlama系列)。虽然仅编码器模型仍主导非微调研究(72.4%),但仅解码器模型占微调实验的65%。仅编码器和编码器-解码器架构日益被定位为比较的基线模型。
3.3 RQ2. 设计了哪些基准、数据集和指标来评估漏洞检测?
本节中,我们将首先检查不同编程语言和关键软件系统中漏洞的分布。然后我们将讨论该领域常用的基准、数据集和指标。由于设计和特性的差异,如C/C++中的内存管理、Python中的不安全反序列化以及Java中的对象注入和反射,不同编程语言具有不同类型的高发漏洞。这尤其重要,因为许多关于LLMs漏洞检测的研究关注语言特定挑战[31, 66, 131]。理解这些细微差别对于评估和提高不同上下文中漏洞检测的有效性至关重要。
我们分析了过去五年(2019-2024年)主要软件系统中的CVE统计,如表3所示。
- 数据截至2024年11月3日从NVD数据库收集
表3揭示了不同软件系统中漏洞分布的几种有趣模式。操作系统(Android、MacOS X、Linux内核和Windows Server)主导漏洞格局,其次是Web浏览器(Chrome和Firefox)和开发平台(Gitlab)。根据CVE统计[20],内存相关漏洞是过去五年中最普遍的类型。作为内存不安全但广泛使用的编程语言,C/C++导致了大量内存损坏漏洞,使得漏洞检测日益紧迫。基于我们对56篇选定论文的分析,我们收集了所有目标编程语言的统计,如图5所示。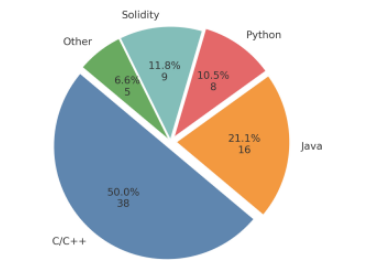
发现一
研究格局显示目标编程语言有清晰分布:C/C++以50%的研究占主导,其次是Java占21.1%。Solidity因在智能合约和金融交易中的关键作用占研究的11.8%。剩余的16.6%覆盖其他语言,包括Python、PHP和Go。
C/C++仍然是漏洞检测的主要焦点,覆盖50%的研究。这一高比例反映了C/C++项目中常见的内存相关漏洞。Java以21.1%排名第二,部分原因是因为其在企业级软件和Android开发中的流行(表3显示Android贡献了大量CVE)。Java的类型系统和字节码格式也为LLMs提供了详细信息,其Web应用程序常面临SQL注入、跨站脚本(XSS)或不安全反序列化。Solidity以11.8%跟随,因为智能合约中的漏洞直接威胁区块链平台上的金融安全。剩余的16.6%包括Python、PHP和Go等语言。
为微调LLMs并测量其在漏洞检测中的性能,研究人员引入了各种数据集,包括BigVul[28]、CVEfixes[6]和Devign[145]。每个数据集针对不同规模,从识别单个函数是否存在漏洞到扫描整个GitHub仓库。这种变化反映了漏洞检测任务的多样化需求。
函数级。 这些数据集的每个数据包含以下属性:函数实现(通常包括修复前和修复后的实现)、漏洞标志(通常1表示有漏洞,0表示无漏洞)。此类常用数据集是BigVul[28]和Devign[145](也称为FFmpeg和QEMU数据集)。这些数据集通常用于微调大型模型和评估LLMs检测漏洞的能力,但它们不太实用。原因是现实世界漏洞通常由跨文件的多个函数引起。
文件级。 一些数据集不仅在函数级别结构化,还在文件级别结构化,如Juliet C/C++[32]和Java[33]测试套件。Juliet测试套件中的一些漏洞在很大程度上模仿了现实世界漏洞的结构,包括但不限于跨文件函数调用或跨文件访问全局变量。这种具有复杂上下文的漏洞为LLM检测漏洞带来了重大挑战。Juliet C/C++测试套件的测试用例501129如图6所示。我们可以看到,在测试用例501129中,引入漏洞的文件和行已在跟踪中标记。这一细节为LLMs检测跨文件引入漏洞的能力提供了线索,但也表明需要提高LLMs检测跨文件漏洞的能力。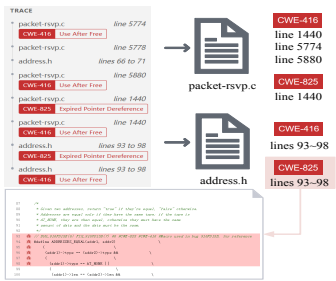
提交级。 许多开源软件使用GitHub平台并通过提交提交修改源代码。显然,受信任的维护者可以提交包含恶意更改的提交,使目标软件易受攻击[120]。因此,也需要对每个提交应用漏洞检测。CVEfixes[6]和Pan2023[93]都是提交级数据集。这些数据集通常包括仓库URL、提交哈希(每个提交的唯一标识符)和差异文件(显示提交前后的差异)。通过这种方式,LLMs可以分析提交前后的代码更改以确定提交是否有漏洞,并通过仓库URL获取上下文信息。
仓库级和应用级。 这些类型的数据集通常用于整个项目的漏洞检测。CWE-Bench-Java[66]是专注于Java项目的仓库级数据集。每个仓库附带有关漏洞的元数据,如CWE ID、CVE ID、修复提交和漏洞版本。这使得分析和验证更加系统和可靠。Ghera[87]是应用级数据集。每个项包含三个应用程序:一个包含漏洞X的易受攻击应用程序、一个可以使用漏洞X攻击易受攻击应用程序的恶意应用程序,以及一个没有漏洞X的安全应用程序。每个项附带构建和运行应用程序的指令,以演示漏洞及其利用,从而验证漏洞的存在与否和利用。提交级数据集的示例如图7所示。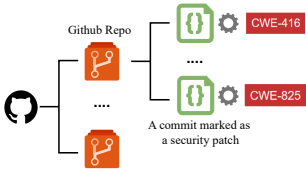
还有其他类型的数据集。例如,随着区块链的兴起,已经建立了智能合约的数据集。这些数据集,如FELLMVP[79],包含许多具有逻辑漏洞(如重入攻击和整数溢出/下溢)的智能合约(合约级)。也有只关注特定漏洞的数据集。例如,Code Gadgets[69]只关注C/C++程序中的两种漏洞类型:缓冲区错误漏洞(CWE-119)和资源管理错误漏洞(CWE-399)。SolidFi[38]只基于注入漏洞。表4显示了漏洞检测中常用的数据集。括号中的数字表示易受攻击项的数量。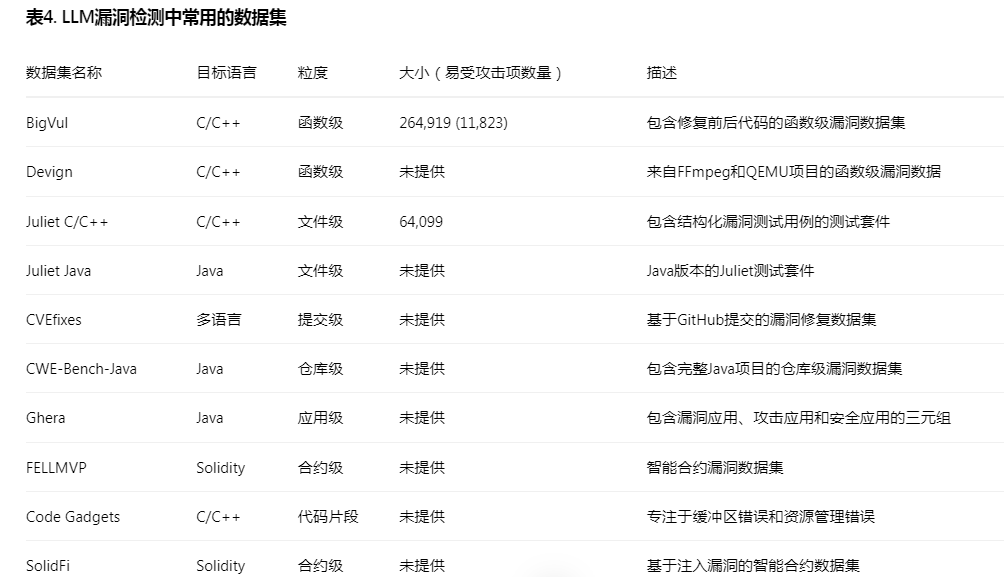
括号中的数字表示易受攻击项的数量。例如,BigVul数据集中共有264,919个函数,其中11,823个易受攻击。
“N/A”表示作者在论文中未提供漏洞数量的详细信息。
发现二
当前漏洞数据集存在两个主要限制:(1)语言不平衡——C/C++约占60%的覆盖范围,而Java尽管在企业级和Android开发中广泛使用,但缺乏全面的数据集;(2)范围差距——严重缺乏反映现实世界开发场景的仓库级数据集,其中漏洞通常跨越多个文件和依赖关系。这种现实、大规模仓库数据集的稀缺对LLMs在漏洞检测中的实际应用构成了关键限制。
LLM-based漏洞检测系统的评估需要多个指标。这些指标可分为三组:分类指标、生成指标和效率指标。
3.3.1 评估指标
3.3.2 分类指标
漏洞检测系统常用几个标准指标:
3.3.3 生成和可解释性指标
为评估生成的漏洞描述质量,Alam等人和Ghosh等人[2, 39]采用BLEU和ROUGE指标。BLEU考虑简洁惩罚和n-gram精确度,而ROUGE测量生成文本与参考文本之间的重叠。这些指标有助于评估基于LLM的漏洞检测系统的准确性和可解释性。
RQ2答案
大多数基于LLM的漏洞检测的基准和数据集关注函数级或文件级范围,C/C++作为主要目标语言。分类指标(如准确率和精确率)被广泛使用,马修斯相关系数(MCC)被用于不平衡数据集。BLEU和ROUGE等指标评估生成描述的质量,而执行时间评估效率。然而,当前数据集受限于对C/C++的关注和仓库级数据的缺乏。这些差距阻碍了LLMs跨语言泛化和检测复杂、多文件漏洞的能力。未来研究应创建多样化、大规模数据集以模拟现实世界场景。
3.4 RQ3. LLM用于漏洞检测使用了哪些技术?
当前,基于LLM的漏洞检测面临几个关键挑战:(1)数据泄露导致性能指标膨胀;(2)难以理解复杂代码上下文;(3)大上下文窗口中的位置偏差导致信息丢失;(4)高误报率和对零日漏洞的性能差。研究人员已进行广泛研究以应对这些挑战。本节总结并讨论当前应用于基于LLM的漏洞检测的技术。
3.4.1 代码数据预处理
代码处理技术有两个主要目标:(1)优化LLMs有限上下文窗口的利用以提高效率;(2)增强LLMs对代码中语义信息的理解以提高漏洞检测能力。
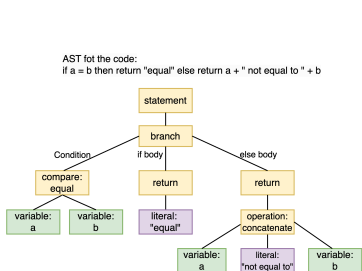
抽象语法树分析。 抽象语法树(AST)提供了程序结构的层次表示,其中代码元素基于其语法关系组织成树格式[118]。这种结构表示消除了非必要语法细节,同时保留了代码组件之间的语义关系。图8表示了一个代码片段的AST。AST在漏洞检测中的应用可分为几种主要方法:代码分割和结构表示,其中AST将代码解析为函数级片段以便在LLMs的上下文限制内高效处理,如Zhou等人[141]和Mao等人[83]所示;语义增强,其中AST与自然语言注释集成形成结构化注释树(SCT),如SCALE框架[119]中实现的那样,以捕获超越语法关系的漏洞模式;多图分析,其中AST与控制流图(CFG)和数据流图(DFG)结合以提供全面的代码结构分析,如DefectHunter[114]所示;与图注意力网络(GATs)集成的模式检测,如VulnArmor[104]、GRACE[77]和[82]所示;以及代码演化中的错误定位,如[137]所示。跨不同数据集(包括FFmpeg、QEMU和Big-Vul)的实证评估表明,AST增强方法显著提高了漏洞检测性能。
数据/控制流分析。 AST缺乏程序数据和控制流的表示。因此,在一些论文[58, 66, 72, 75, 77, 106]中,数据流图(DFG)和控制流图(CFG)已被应用以帮助LLMs理解程序中的过程间数据流和控制流。图9是说明Java方法及其对应DFG的简明示例。DFG总结了程序中的可能执行路径,使用节点(或基本块,即顺序执行而无任何分支操作的语句)表示程序结构,边表示数据流。CFG具有与节点相同的基本块,但边用于表示基本代码块之间的分支操作。DFG/CFG主要有两种用法:在提示中提供额外上下文信息和知识库。将源代码与其DFG和CFG结合到提示中将显著提高LLM识别漏洞的性能[58, 72, 75, 77];Sun等人提出DFG和CFG可用于知识库,通过基于图的相似性搜索算法,为LLMs提供具有相似数据和控制流结构代码段的信息[106]。除了DFG和CFG,调用图已用于漏洞检测[79],为LLM提供有关函数间依赖关系的更多信息。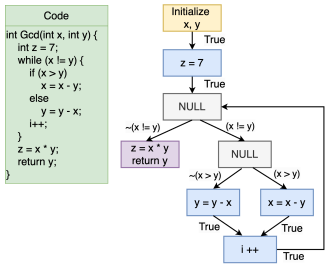
检索增强生成。 检索增强生成(RAG)通过集成信息检索系统来增强LLMs的能力,该系统为LLMs提供额外相关信息[62]。图10说明了RAG的原理。LLMs接收用户输入并应用搜索器从知识库中查找相关文档或信息片段。检索到的信息与原始提示结合生成响应。通过这种方式,RAG可以解决LLMs在某些领域知识不足、幻觉以及大语言模型无法实时更新数据的问题。许多论文讨论了在构建LLMs的RAG时如何选择正确知识作为高优先级[12, 57, 59, 86, 106]。Cao等人直接使用CWE数据库作为外部知识[12]。许多论文关注将代码片段、静态分析结果与相应漏洞文档结合作为知识[57, 59, 86]。除了上述知识,Sun等人使用GPT-4总结现有知识从而创建两个知识库(带漏洞报告的VectorDB和总结知识)[106]。RAG已被证明能提高LLM检测漏洞的能力[57]。
程序切片。 程序切片技术已用于减少与漏洞无关的代码行并保留与触发漏洞相关的关键行[13, 82, 96, 137]。Purba等人应用程序切片技术提取用于缓冲区溢出检测的代码片段[96]。这些代码片段通常包含关键函数,如strcmp和memset,以及调用这些函数的相关语句。Cao等人以类似方式使用程序切片[13]。他们首先找到所有潜在漏洞触发器,然后应用程序切片技术收集与这些触发器相关的所有语句。虽然Purba等人[96]和Cao等人[13]仅将程序切片技术用于代码预处理,但Zhang等人提出通过切片代码微调LLMs以提高LLMs漏洞检测的性能[137]。不是设置显式切片标准,LLMs在训练期间学习从给定函数中分离易受攻击代码行。这种方法帮助模型关注代码的相关部分并更准确地识别漏洞。程序切片技术已被证明能提高LLMs检测漏洞的能力[96, 137]。
LLVM中间表示。 通过将源代码转换为LLVM中间表示(IR)[61],分析和检测方法不需要专门适应不同编程语言。这提高了漏洞检测方法的多功能性,且LLVM IR还保留了程序结构和语义,使LLM更容易分析代码中的潜在依赖关系。但缺点明显:LLVM IR不适用于Java和Javascript。为使方法可泛化到编程语言,作者将源代码转换为LLVM IR并在这些IR上训练LLMs[82]。
我们可以看到,在LLMs漏洞检测领域,技术主要来自传统软件分析和LLM研究。基本上,这些技术的输出用作提示的一部分,以评估LLMs的漏洞检测能力。这些方法不仅优化了LLMs上下文窗口的利用效率,还通过保留或提取代码中的语义信息提高了其对潜在漏洞的理解。然而,它也不可避免地增加了令牌消耗,并且存在提示内容过多可能降低LLMs检测漏洞能力的可能性。
发现三
我们的分析显示,41.3%的研究采用了代码处理技术——包括图表示、检索增强生成(RAG)和代码切片——以更好地利用LLMs的有限上下文窗口。虽然这些方法相比直接代码提示显示出适度改进,但在处理复杂、跨文件漏洞时其有效性显著降低。值得注意的是,随着更大LLMs(如GPT系列)的出现,模型本身的性能增益往往超过代码处理技术的增益。这表明,虽然当前代码语义处理方法提供了好处,但开发更有效的复杂代码上下文表示方法仍然是关键挑战。
3.4.2 提示工程技术
这是优化基于LLM的漏洞检测系统最广泛使用的策略之一,因为它通过定制输入提示实现对模型响应的精确控制。
思维链提示。 思维链(CoT)提示是一种技术,其中LLMs被引导遵循逐步指令,在生成最终输出前增强推理准确性。图11说明了漏洞检测的CoT推理过程。在基于LLM的漏洞检测中,CoT提示涉及指示模型首先总结给定代码的功能,然后评估可能引入漏洞的潜在错误,最后确定代码是否易受攻击。这种结构化提示策略已被证明通过帮助模型以更有组织的方式推理复杂代码来提高漏洞检测任务中的精确率和召回率。然而,虽然CoT提示通常提高精确率,但其对召回率的影响在不同场景下可能不同[106]。
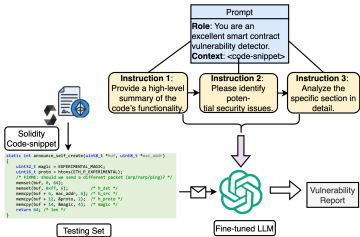
少样本学习。 在基于LLM的漏洞检测中,少样本学习(FSL)使模型能够利用提示中的一小部分标记示例来提高任务特定性能。在这种方法中,漏洞检测可以通过将分类标准(如CWE)直接嵌入提示中来增强[37]。通过合并CWE漏洞类别——包括编号和描述性名称——模型获得有助于准确识别和分类漏洞的上下文知识。图11也说明了少样本学习的原理,其中模型在分析新测试集前被提供标记示例(如Solidity Code 1和Solidity Code 2)以理解任务。这些示例与任务特定提示结合,指导微调后的LLM生成准确输出。
分层上下文表示。 分层上下文表示是一种用于在分析广泛代码库时管理LLMs上下文长度限制的技术。在漏洞检测中,代码可以分层组织为模块、类、函数和语句。通过以这种分层方式表示代码,LLM可以在不同抽象级别处理和分析代码。这种方法允许模型在深入详细代码段前关注更高级结构,有效管理上下文并在LLMs的最大输入长度限制内改进漏洞检测。
多级提示。 多级提示策略涉及将漏洞检测任务分解为多个提示,每个提示针对特定分析级别。不是将整个代码和任务呈现在单个提示中,该策略将过程分为阶段。例如,第一个提示可能要求LLM提供代码功能的高级摘要。第二个提示可能关注识别潜在安全问题,后续提示可能请求特定部分的详细分析。这种分层方法帮助LLM系统处理复杂代码,通过一次关注一个方面增强其检测漏洞的能力。图10说明了多级提示的实例。
多提示代理和模板。 该技术使用几个专门的提示代理,每个代理设计有特定模板以在漏洞检测过程中执行不同角色。例如,一个代理可能负责使用指导LLM提取关键功能的模板进行代码摘要。另一个代理可能关注漏洞识别,利用提示模型查找常见安全弱点的模板。通过使用具有定制模板的多个代理,系统利用每个专门提示的优势,导致更准确和全面的漏洞检测结果。
总的来说,提示工程有效性随模型大小变化。小模型受益于少样本学习和结构化提示以补偿有限能力,而大模型因更强的泛化能力和领域知识,在思维链提示和零样本方法下表现更好。
发现四
随着LLMs固有能力的增长,其上下文窗口容量相应扩展。思维链(CoT)提示成为大型模型(>100亿参数)的主导方法,100%的最新研究采用CoT来增强生成。对于文本处理能力有限的小型模型,零样本或最小少样本方法证明更有效,因为CoT和额外的少样本示例可能导致不相关输出。
3.4.3 微调
微调帮助大语言模型(LLMs)更好地学习特定任务。它通过使用这些任务的新数据重新训练预训练模型来工作。微调对三个主要原因很重要[129, 140]:(1)代码中的安全问题遵循LLMs必须学习发现的特殊模式;(2)计算机代码与普通文本不同,因此LLMs需要学习如何更好地阅读和理解代码;(3)发现安全问题需要非常准确——遗漏真实问题或报告错误问题都会导致严重问题。如表5所示,约30%的研究选择微调现有LLMs作为其主要提出的方法。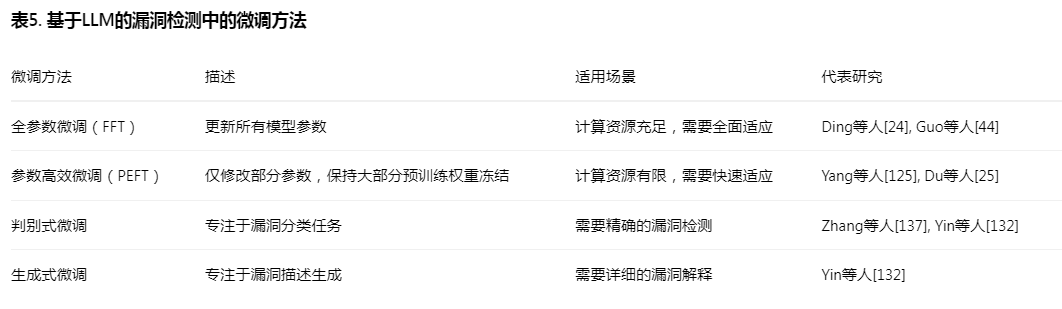
全参数微调(FFT)。FFT在训练期间更新所有模型参数。由于计算限制,大多数研究利用参数少于150亿的模型,如CodeT5、CodeBERT和UnixCoder。Ding等人[24]在70亿参数下实验了五个模型,即使在PrimeVul上训练和验证也仅达到0.21 F1分数。Guo等人[44]使用CodeBERT进行FFT 50轮,在PrimeVul上达到0.099 F1分数,但在Choi2017数据集上达到0.66 F1分数。Haurogne等人[46]在DiverseVul数据集上达到0.69 F1分数,而Purba等人[96]在缓冲区溢出检测中达到0.73 F1分数。
参数高效微调(PEFT)。PEFT方法仅修改参数子集,同时保持大多数预训练权重冻结。适配器在原始模型层之间引入额外的可训练层,Yang等人[125]在故障定位中达到60% Top-5准确率。LoRA将权重更新表示为低秩分解,Du等人[25]等研究达到0.72 F1分数,Guo等人[44]在各自数据集上达到0.97 F1分数。QLoRA结合参数量化和LoRA,Boi等人[7]证明以更低内存使用达到59%准确率。
判别式微调)。对于标记序列 X={x
1
,x
2
,…,x
L
},模型处理它以输出漏洞标签。Zhang等人[137]和Yin等人[132]证明,微调后的CodeLlama相比未微调对应物实现0.62 F1分数改进。
生成式微调)。该方法支持序列到序列学习,用于生成结构化输出,如漏洞描述或易受攻击行识别。Yin等人[132]显示,在生成任务中微调预训练LMs优于微调LLMs,CodeT5+达到0.722 ROUGE分数,而DeepSeek-Coder 6.7B为0.425。

发现五
微调通过全参数和参数高效方法(PEFT)增强基于LLM的漏洞检测。具有PEFT的大型模型(>100亿)实现最佳结果,而基础模型如GPT-4和CodeLlama提供接近0.9的F1分数。判别式策略在精确检测中表现优异,需要至少10K样本的数据集。然而,计算限制和数据集质量仍然是关键挑战。
RQ3答案
基于LLM的漏洞检测技术分为三类。首先,代码预处理——如AST分析、数据/控制流分析、RAG和程序切片——增强上下文利用但在复杂、跨文件漏洞方面挣扎。其次,提示工程——如CoT提示、少样本学习和专门代理——提高准确性,大型模型(>100亿)受益于思维链方法,而较小模型偏好更简单提示。最后,微调——全参数和参数高效方法如LoRA——实现接近0.9的F1分数,特别是在大型模型中。随着模型进步,其固有优势可能超过预处理好处,突出需要解决复杂上下文和跨文件漏洞。
3.5 RQ4. LLMs在检测漏洞时面临哪些挑战及解决它们的潜在方向?
该领域目前面临四个主要挑战,以及相应的潜在方向,如图12所示。首先,研究人员难以获得高质量数据集。其次,大语言模型(LLMs)在处理复杂漏洞时效果降低。第三,这些模型在现实世界仓库应用中成功有限。第四,模型缺乏强大的生成能力。多项研究证实这些挑战是进展的主要障碍。以下各节详细检查每个挑战。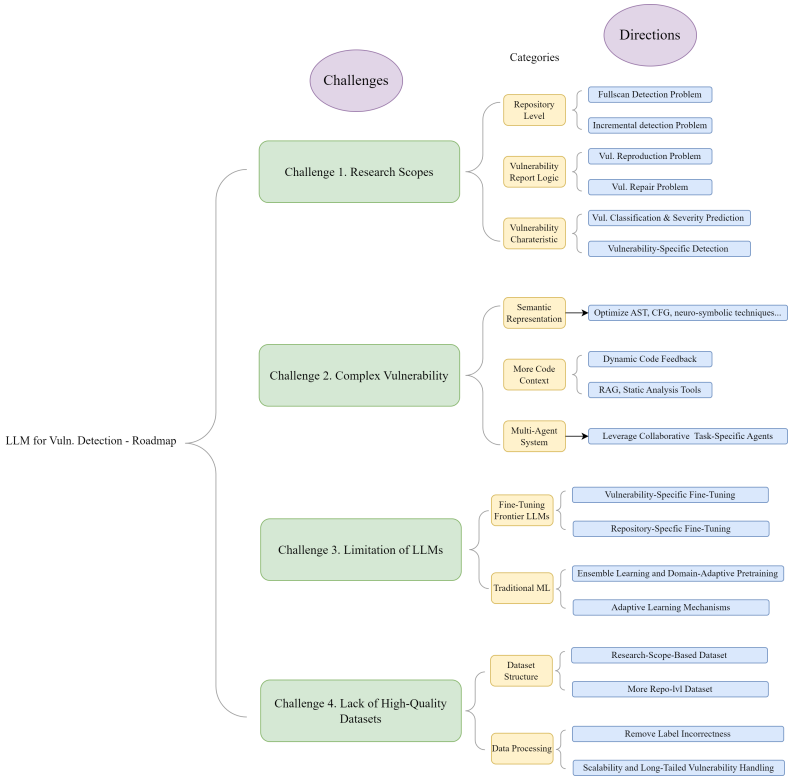
挑战1:研究问题范围有限:当前研究主要专注于确定给定代码片段是否易受攻击。在本综述中,约40项研究(83%)专注于分析孤立代码片段,其中LLM性能通常超过现实世界代码检测场景中观察到的结果[37]。虽然这为评估提供了受控环境,但它忽略了实际应用中的复杂性,如分析整个代码库或解决协作开发期间出现的漏洞。这表明仅关注孤立函数或片段的研究对现实世界场景用处有限。
潜在方向:除了分析孤立代码段,未来研究应围绕现实世界开发中的以下关键问题构建:
按开发中代码演化分类的研究问题:
- 全量/增量检测:全量检测需要分析跨多个文件的整个代码库,而增量检测关注新代码提交。当前LLMs擅长分析孤立代码段,但在更广泛上下文方面挣扎[53]。因此,LLMs通常协助静态分析工具或支持模糊测试任务[80, 126, 127],而非执行独立分析。对于提交级检测,现有方法将提交与静态分析结果结合[63, 128],但在遇到训练语料库外API时可能失败[53]。
按漏洞报告工作流分类的研究问题:
- 复现漏洞:漏洞复现将是未来研究的关键,也是减少误报的关键。对于每个检测到的漏洞,LLMs应尝试使用输入驱动(如模糊器)复现[53]。通过生成触发潜在漏洞的输入,LLMs可以提供漏洞存在的证据[122, 126]。该方法验证检测并确保发现可操作,从而提高漏洞报告可靠性。
- 修复漏洞:虽然许多研究讨论了漏洞修复,但在现实世界项目中的实际实施仍然具有挑战性[143]。生产环境中成功的漏洞修复必须满足几个标准。
- 修复代码必须通过所有现有测试
- 修复代码必须防止漏洞复现
- 修复代码不应引入新漏洞
- 当前数据集质量和LLM能力的限制阻碍了有效的漏洞修复验证。虽然LLMs可以识别易受攻击代码,但它们经常错误识别漏洞位置,导致不正确解释和修复。生成概念验证利用和模拟程序操作的能力将改进验证,但这需要LLM能力的显著进步[60]。
按漏洞特征分类的研究问题:
专门化漏洞检测:针对特定漏洞类别的定向检测方法开发代表了一个重大挑战。当前研究[36]证明LLMs在不同漏洞类型间表现出不同能力——在检测越界写入漏洞(CWE-787)时达到高准确率,而在缺失授权问题(CWE-862)上表现差。这种性能变化需要针对不同CWE类别的专门检测机制,特别是对于高频漏洞(如内存相关问题)。缺乏类别特定研究和数据集使这一关键领域 largely unexplored。
漏洞分类和严重性评估:Alam等人[2]和Gao等人[36]强调两个基本挑战:首先,根据既定框架(如CWE)准确分类检测到的漏洞仍然困难。此分类问题对实际开发工作流至关重要,因为不同漏洞类型需要不同的修复方法。其次,预测漏洞严重级别直接影响修复优先级和时间表,高风险漏洞需要加速缓解。
发现六
在选择实验研究问题时,研究人员应优先考虑解决软件漏洞检测中的现实世界挑战。例如,研究可按代码库分析方法分类,如全量扫描或增量扫描,专注于全面或提交级漏洞检测。此外,基于现实世界开发中漏洞报告的邏輯工作流,研究可分为漏洞发现、复现和修复。除此之外,其他可行方向包括漏洞分类、严重性预测和针对特定漏洞类型的定向检测。
挑战2:漏洞语义表示的复杂性。漏洞模式通常非常复杂[65]。超过95%的研究报告代码复杂性——如外部依赖、多个函数调用、全局变量和复杂软件状态——使漏洞检测困难。我们可以通过代码行数或圈复杂度[108]测量此复杂性,并使用程序依赖图(DFGs)或调用图可视化它。然而,大多数方法关注函数或文件级别的单个代码块[25, 137],这对大项目帮助不大。处理复杂项目时,LLMs通常输入有限且面临许多”未见代码”[53]。
在更简单情况中——如来自合成数据集约500行的单个函数——LLMs可以很好检测漏洞,即使在零样本设置中[13, 122]。但许多研究表明需要更多信息处理更大项目[3, 37],特别是在在线语料库稀疏时。这种情况下,我们必须提供额外文档和规范[136]。此外,一些函数依赖其调用者进行保护,因此单独分析它们可能导致不正确结论。我们需要给LLMs足够上下文以准确识别漏洞。
潜在方向:两个核心方法可以应对此挑战。第一种方法专注于使LLMs能够阅读更多代码。这增加了它们对整个仓库的理解。第二种方法强调使用抽象表示简化代码语义。这增强了LLMs对代码结构和行为的理解。
- 动态代码知识扩展:通过反馈循环和自适应机制,应使LLMs能够自由访问和理解仓库代码[127, 136]。这将通过为漏洞分析提供更广泛上下文来解决高误报率。
- 优化代码表示:研究[58, 72, 75, 77, 106]利用AST、CFG和DFG表示减少有限上下文窗口的令牌数。虽然当前实现尚未显著改进检测准确率,但未来研究机会包括复杂语义处理、多方法集成、更好上下文保存和混合图表示。
- 专门化LLM代理:研究探索通过专门化LLM代理进行优化。研究[115]证明任务划分在多个代理间增加输出稳健性。每个代理
专门化LLM代理研究 探索通过专门化LLM代理进行优化。研究[115]证明任务划分在多个代理间增加输出稳健性。每个代理专注于漏洞检测的特定方面。提示工程研究[75]评估零样本、少样本和思维链方法对检测准确性的影响。然而,代码复杂性引入挑战。多个代理在复杂代码上显示准确性下降。少样本和思维链方法无法提供足够的额外上下文。
与外部工具集成 外部工具提供重要支持机制。LangChain通过简化和异步LLM调用提高效率。检索增强生成(RAG)因其成本效益和效率而广受欢迎。研究[12, 26]实现RAG将代码上下文向量化,并通过基于LLM的检索增强检测。然而,代码上下文与自然语言有根本区别。这种差异需要代码语义提取、存储和比较的专门方法。
这些优化技术可能弥合LLMs当前能力与大型代码库中现实世界漏洞检测复杂需求之间的差距。
发现七
漏洞的复杂性表明易受攻击代码通常涉及复杂的控制流。解决此问题需要提高LLMs高效存储和处理代码信息的能力。研究人员可以使用检索增强生成(RAG)或类似工具动态扩展知识。代码语义可以使用控制流图(CFGs)、抽象语法树(ASTs)或神经符号方法压缩。此外,可以在漏洞检测系统中使用针对特定任务优化的专门代理。这些方法提高了LLMs处理复杂代码结构的效率和有效性。
挑战3:LLMs的内在限制。检测解决方案必须保持对数据变化和对抗攻击的稳健性[25]。然而,Yin等人[132]的研究揭示LLMs缺乏这种稳健性。它们显示对数据扰动的脆弱性。这些发现表明需要更可靠的方法。
此外,LLMs需要更好的可解释性和一致性以用于现实世界应用。Haurogne等人和Du等人[25, 46]证明LLMs产生不一致的漏洞解释。它们无法保证每个实例的正确解释。输出在不同运行间显示随机性。即使LLMs正确识别易受攻击代码,它们也经常无法提供准确的漏洞解释。此限制对后续修复和审查过程造成显著问题。此领域的当前研究仍然不足。
未来研究应聚焦这些关键领域:提高准确性、增强稳健性、增加输出可靠性和可解释性。这些改进将使基于LLM的解决方案更适用于现实世界使用。
潜在方向:此挑战的核心是提高LLMs固有的漏洞检测能力。研究人员可能聚焦训练新模型或微调LLMs。
微调前沿LLMs:关于缩放定律的最新发现[56]表明,更大的仅解码器语言模型,如GPT-4和Claude3.5-Sonnet,可以在模型大小、训练数据和计算缩放时实现系统性能改进。模型能力的改进增强漏洞检测、分类和解释。Alam等人[2]的研究显示,在相同提示下,GPT-4和GPT-3.5比早期模型如Llama2和CodeT5实现更高检测准确性。GPT-O1的发布,以其可见的推理过程,表明检测能力和输出可解释性的改进。微调方法显示前景。几项研究[2,13,25,44,81,84]微调开源模型如CodeLlama和CodeBERT。这些实现与通用LLMs相当的结果。然而,数据集限制呈现挑战。研究[113]表明实际应用需要至少100,000示例的数据集。这造成显著的训练成本障碍。研究人员可以通过以下方法增强漏洞检测性能:
- 漏洞特定微调:在特定漏洞类型上微调模型。研究[2,13,25]显示在特定漏洞类别(如内存相关问题、注入缺陷)上训练的模型实现更高检测准确性。此定向方法允许模型在每个漏洞类型内学习更深模式。
- 仓库自适应微调:通过在仓库特定数据上微调使模型适应特定代码库。研究[45, 82]证明此方法通过帮助模型理解项目特定编码模式和架构改进检测准确性。此方法受益于具有独特编码约定的大型复杂项目。
集成学习和领域自适应预训练:结合来自多个模型的预测有效减少误报并改进检测准确性。DAPT可以通过利用包括公共记录(如NVD)和领域特定数据的策划数据集细化LLMs对特定上下文的理解。这实现更好识别利基漏洞和改进泛化。
- 自适应学习机制:为解决安全威胁的动态性质并增强模型稳健性,自适应学习[85]机制允许通过反馈循环和定期再训练进行连续知识更新。高级优化技术可以进一步改进提示配置和学习率,确保现实世界应用中的可靠性。
发现八
增强LLMs的稳健性和可解释性对有效漏洞检测至关重要。在特定漏洞类型(如内存问题或注入缺陷)上微调通过聚焦定向模式改进检测准确性。仓库自适应微调帮助模型学习项目特定编码约定,进一步提高准确性。集成学习结合来自多个模型的预测以减少误报,而领域自适应预训练(DAPT)使用策划数据集细化模型对利基上下文的理解。结合反馈循环和定期更新的自适应学习机制确保LLMs对演进威胁保持稳健。这些方法解决LLM限制并改进其现实世界适用性。
挑战4:高质量数据集的缺乏。高质量漏洞基准数据集仍然稀缺。当前数据集面临几个问题。这些包括数据泄露、不正确标签、小规模和有限范围[17, 86, 121]。
数据集不正确性:这些挑战中的关键问题是漏洞的错误标签,这损害数据集的可靠性和有效性。自动化收集方法[89]可以快速收集大量数据但无法确保正确标签而无需人工审查,导致许多误标或不准确注释样本。研究[121]也显示频繁数据泄露,因为LLMs经常训练于来源如GitHub、旧软件版本和外部库,版本控制或去重不足。结果,模型可能在测试期间遇到训练期间看到的相同数据,膨胀性能指标并破坏现实世界有效性。总之,漏洞检测的高质量数据集应满足几个要求。
- 准确标签:由于标签在监督学习中至关重要,不正确注释可能导致生产环境中的严重问题。
- 最小数据泄露:在广泛代码库上训练的大规模LLMs风险在测试期间看到相同漏洞。对策包括代码混淆、合成和使用更新数据集。
- 全面注释:对于仓库级数据,提供复现漏洞的调用序列和控制流,以及详细描述,帮助LLMs创建更可靠检测报告。
**潜在方向:解决此挑战的关键在于研究人员聚焦基于特定研究范围构建数据集。如挑战1中讨论,基于LLM的漏洞检测中的不同研究问题需要不同类型的数据集,所有这些目前缺乏足够的准确数据或案例。研究人员应以聚焦特定研究问题的定向方式处理数据集构建。研究可以开发于:
- 数据集质量和范围增强:研究可以聚焦开发更小、高质量测试集以有效测量漏洞检测进展。一种方法结合来自多项研究[2,73,147]的现有验证样本。这创建研究社区可以随时间维护和扩展的可靠测试基准。此外,LLMs的最新进展,特别是具有128k上下文窗口的GPT-4o,实现全面仓库级漏洞分析,允许研究人员检测和修复整个代码库中的漏洞而非仅函数级。
- 可扩展性和长尾漏洞处理:处理漏洞类型的长尾分布需要可扩展模型和数据增强技术[23,71]。为稀有漏洞类型生成合成样本可以改进LLMs检测低频率事件的能力。集成结构化信息,如CWE分类,可以进一步增强模型优先处理和处理关键漏洞的能力[5]。
发现九
高质量数据集对推进基于LLM的漏洞检测至关重要。具有详细注释(包括调用序列和控制流)的仓库级数据集增强现实世界适用性。与特定研究范围对齐的定向数据集解决独特检测挑战。合成数据生成减轻数据泄露并处理稀有漏洞类型。结合验证样本与可扩展数据增强确保仓库范围漏洞检测的稳健基准。
RQ4答案
基于LLM的漏洞检测的主要挑战包括研究范围、数据集质量、漏洞复杂性和模型稳健性。关键研究方向涉及改进模型能力、开发高级使用方法、增强数据集、加强检测稳健性和专门化漏洞检测方法。仍有长路要走。
4 限制
几个因素可能影响本综述的全面性。首先,约60%的基于LLM的漏洞检测研究以预印本形式出现在arXiv上。这反映了该领域的新兴性质。其次,概念中的术语变化,如”LLM”和”漏洞检测”,可能导致初始搜索中的遗漏。为减轻这些风险,我们实施了系统方法。我们通过分析已建立会议和期刊的已发表论文开始。我们从这些来源提取核心关键词。在两个月期间,我们从约500篇论文优化选择至58项高度相关研究。本综述的未来版本将纳入此快速演进领域的新发展。此持续过程将确保更全面和及时的研究文献覆盖。
5 结论
本研究呈现了LLMs在漏洞检测中应用的系统分析。通过广泛文献回顾,我们提供当前研究景观的全面检查,系统解决四个关键问题:LLMs在漏洞检测中的应用、评估基准和数据集的设计、当前技术方法和现有挑战与未来方向。
我们的发现证明LLMs在代码理解和漏洞检测中展示显著潜力。通过微调和提示工程技术,LLMs可以有效改进检测准确性。跨多个基准数据集的实验表明,最近的大规模LLMs,如GPT-4和Claude-3.5,在漏洞检测任务中实现了显著进展。然而,在将LLMs应用于实际安全开发中仍存在重大挑战。主要障碍是高质量数据集的稀缺,这约束模型训练和评估。此外,当前LLMs在处理复杂代码结构和仓库级漏洞检测中显示显著限制。此外,关于输出随机性和模型可解释性的问题需要进一步调查。
基于这些发现,我们提出几个有前景的研究方向:增强模型对代码演化的适应、改进漏洞复现和修复能力、开发高质量数据集和加强模型稳健性和可解释性。这些领域的进展将推动LLMs在漏洞检测中的更广泛采用。
未来,我们计划通过添加更多漏洞相关任务(如漏洞定位、漏洞评估和漏洞修补)来丰富此综述。